为了在命令行程序中实现和用户的交互,我们编写的程序的运行过程中往往涉及到对标准输入/输出流的多次读写。
在C语言中接受用户输入这一块,有着一个老生常谈的问题:“怎么样及时清空输入流中的数据?”
这也是这篇小笔记的主题内容。

在此点击/悬停可进行调节
拖拽蓝/紫块以调节进度/音量
先从缓冲区说起。
缓冲区是内存中划分出来的一部分。通常来说,缓冲区类型有三种:
- 全缓冲
- 行缓冲
- 无缓冲
# 行缓冲
在C语言中缓冲区这个概念的存在感还是挺强的,比较常用到的缓冲区类型则是行缓冲了,如标准输入流 stdin 和标准输出流 stdout一般(终端环境下)就是在行缓冲模式下的。
行缓冲,顾名思义,就是针对该缓冲区的I/O操作是基于行的。
-
在遇到换行符前,程序的输入和输出都会先被暂存到流对应的缓冲区中
-
而在遇到换行符后(或者缓冲区满了),程序才会进行真正的I/O操作,将该缓冲区中的数据写到对应的流 (stream) 中以供后续读取。
就标准输入stdin而言,用户的输入首先会被存到相应的输入缓冲区中,每当用户按下回车键输入一个换行符,程序才会进行I/O操作,将缓冲区暂存的数据写入到stdin中,以供输入函数使用。
而对标准输出stdout来说,输出内容也首先会被暂存到相应的输出缓冲区中,每当输出数据遇到换行符时,程序才会将缓冲区中的数据写入stdout,继而打印到屏幕上。
这也是为什么在缓冲模式下,输出的内容不会立即打印到屏幕上:
#include <stdio.h>
int main()
{
// 设置缓冲模式为行缓冲,缓冲区大小为10字节
setvbuf(stdout, NULL, _IOLBF, 10);
fprintf(stdout, "1234567"); // 这里先向stdout对应的缓冲区中写入了7字节
getchar(); // 这里等待用户输入
printf("89"); // 再向stdout对应的缓冲区中写入了2字节
getchar(); // 接着等待用户输入
printf("Print!"); // 再向stdout对应的缓冲区中写入了6字节
getchar(); // 最后再等待一次用户输入
return 0;
}
运行效果:

可以看到,直到执行到第二个getchar()时,屏幕上没有新的输出。
而在执行了printf("Print!")之后,输出缓冲区被填满了,输出缓冲区中现有的10字节的数据被写入到stdout中,继而才在屏幕上打印出123456789P。
缓冲区内容被读走后,剩余的字符串rint!接着被写入输出缓冲区。程序运行结束后,输出缓冲区中的内容会被全部打印到屏幕上,所以会在最后看到rint!。
# C语言中常用的输入函数
输入函数做的工作主要是从文件流中读取数据,亦可将读取到的数据储存到内存中以供后续程序使用。
# 基于字符
// 从给定的文件流中读一个字符 (fgetc中的 f 的意思即"function")
int fgetc( FILE *stream );
// 同fgetc,但是getc的实现*可能*是基于宏的
int getc( FILE *stream );
// 相当于是getc(stdin),从标准输入流读取一个字符
int getchar(void);
// 返回获取的字符的ASCII码值,如果到达文件末尾就返回EOF(即返回-1)
# 基于行
// 从给定的文件流中读取(count-1)个字符或者读取直到遇到换行符或者EOF
// fgets中的f代表“file”,而s代表“string”
char *fgets( char *restrict str, int count, FILE *restrict stream );
// 返回指向字符串的指针或者空指针NULL
# 格式化输入
// 按照format的格式从标准输入流stdin中读取所需的数据并储存在相应的变量中
// scanf中的f代表“format”
int scanf( const char *restrict format, ... );
// 按照format的格式从文件流stream中读取所需的数据并储存在相应的变量中
// fscanf中前一个f代表“file(stream)”,后一个f代表“format”
int fscanf( FILE *restrict stream, const char *restrict format, ... );
// 按照format的格式从字符串buffer中截取所需的数据并储存在相应的变量中
// sscanf中的第一个s代表“string”,字符串
int sscanf( const char *restrict buffer, const char *restrict format, ... );
// 返回一个整型数值,代表成功根据格式赋值的变量数(arguments)
# 最常到的输入流问题
先来个不会出问题的示例:
#include <stdio.h>
int main()
{
char test1[200];
char test2[200];
char testChar;
printf("Input a Character: \n");
testChar = getchar();
fprintf(stdout, "Input String1: \n");
scanf("%s", test1);
fprintf(stdout, "Input String2: \n");
scanf("%s", test2);
printf("Got String1: [ %s ]\n", test1);
printf("Got String2: [ %s ]\n", test2);
printf("Got Char: [ %c ]\n", testChar);
return 0;
}
运行效果:

出问题的示例:
#include <stdio.h>
int main()
{
char test[200];
char testChar1, testChar2, testChar3;
fprintf(stdout, "Input String: \n");
scanf("%3s", test);
printf("[1]Input a Character: \n");
testChar1 = getchar();
printf("[2]Input a Character: \n");
testChar2 = fgetc(stdin);
printf("[3]Input a Character: \n");
testChar3 = getchar();
printf("Got String: [ %s ]\n", test);
printf("Got Char1: [ %c ]\n", testChar1);
printf("Got Char2: [ %c ]\n", testChar2);
printf("Got Char3: [ %c ]\n", testChar3);
return 0;
}
运行效果:

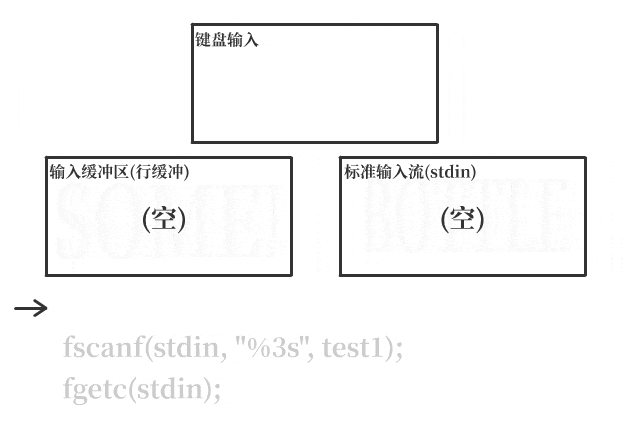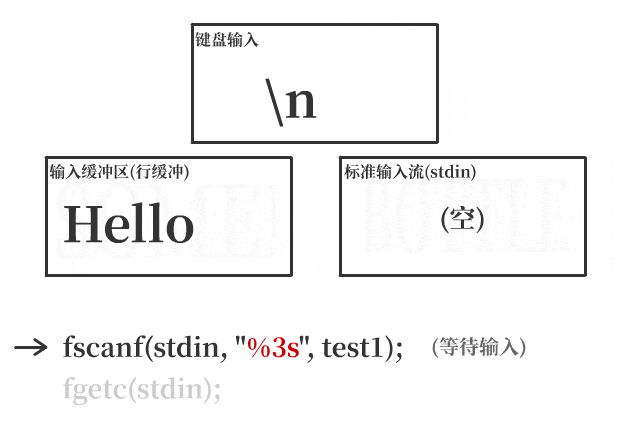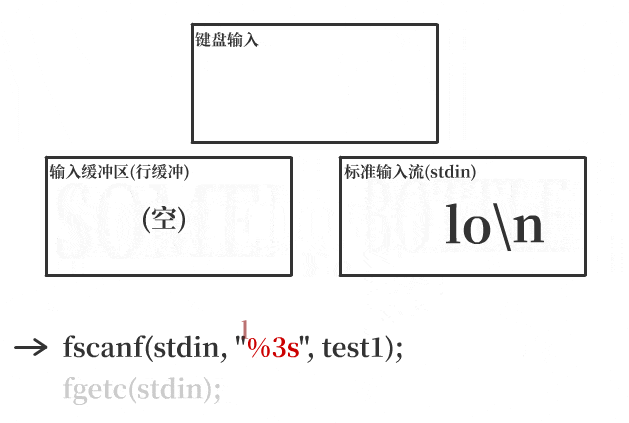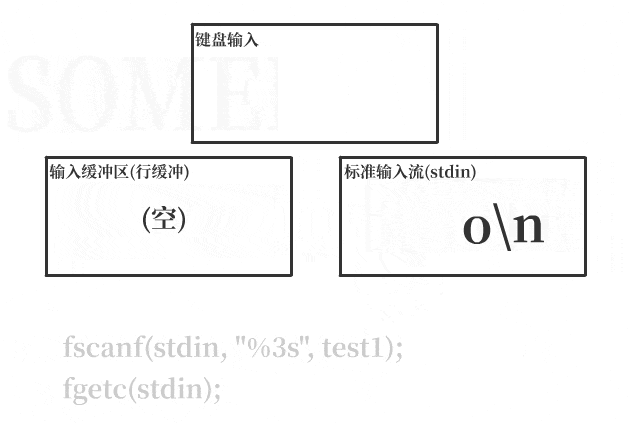
因为我将格式设置为了%3s,所以scanf最多接收包含三个字符的字符串。
在这个示例中,我按要求输入了一条字符串Hello,并按下回车输入一个换行符,缓冲区数据Hello\n被写入到了stdin中。而scanf只从标准流stdin中读走了Hel这一部分字符串。
此时,标准流stdin中实际上还剩3个字符:
lo\n(回车输入的换行符)
于是接下来三次针对字符的输入函数只会分别从stdin中取走这三个字符,而不会等待用户输入,这就没有达到我想要的效果。
在基本的命令行程序中很容易遇到这类问题,这也是为什么需要及时清空输入流stdin中的数据。
# 如何处理残余内容
💡 以下内容假设stdout和stdin两个标准流都是在行缓冲模式下的。
# 标准输出流stdout
虽然本文主要是写输入流,但这里我还是掠过一下标准输出流stdout。C语言标准库中提供了一个用于刷新输出流缓冲区的函数:
int fflush( FILE *stream );
// 如果成功了,返回0,否则返回EOF(-1)
要清空标准输出流对应的缓冲区,只需要使用fflush(stdout)即可。上面的这个例子可以修改成这样:
#include <stdio.h>
int main()
{
// 设置缓冲模式为行缓冲,缓冲区大小为10字节
setvbuf(stdout, NULL, _IOLBF, 10);
fprintf(stdout, "1234567"); // 这里先向stdout对应的缓冲区中写入了7字节
fflush(stdout); // 刷新缓冲区,将缓冲区中的数据写入到标准输出流中
getchar(); // 这里等待用户输入
printf("89"); // 再向stdout对应的缓冲区中写入了2字节
fflush(stdout);
getchar(); // 接着等待用户输入
printf("Print!"); // 再向stdout对应的缓冲区中写入了6字节
getchar(); // 最后再等待一次用户输入
return 0;
}
运行效果:

可以看到,加入fflush(stdout)后,输出缓冲区的内容会被及时写入stdout中,继而打印到屏幕上。
值得注意的是,fflush(stdin)的行为是未定义(不确定)的:
For input streams (and for update streams on which the last operation was input), the behavior is undefined.
不同平台的编译器对此有不同的解释。
-
比如在Windows平台上,无论是
VC6.0这种目前一些学校教学还在使用的古董编译器,还是gcc 8.x.x,大体还是支持通过这种操作清空输入流的。 -
但是在Linux平台上的
gcc编译器就不买账了,是不支持fflush(stdin)这种操作的。
因此,尽量避免fflush(stdin)这种写法,这十分不利于代码的可移植性。
# 标准输入流stdin
上面提到因为可移植性要避免fflush(stdin)这种写法,接下来记录一下可移植性高的写法。
# 接受格式化输入时去除多余空白符
这一种其实用的比较少,但我觉得还是得记一下。
whitespace characters: any single whitespace character in the format string consumes all available consecutive whitespace characters from the input. Note that there is no difference between "\n", " ", "\t\t", or other whitespace in the format string.
上面这段解释来自于cppreference,也就是说,格式化字符串中的空白符(如"\n", " ", "\t\t")会吸收输入字符串中的一段连续的空白符。
也就是说,下面这句格式化输入函数:
scanf(" %c %c",&recvChar1,&recvChar2);
可以从stdin中读取形如 \n a b, \t a b这样的数据。其中a之前的空白符和a与b之间的空白符都会被吸收,scanf得以能准确获取字符a和b。
依靠这个特性,我们可以在接收输入时自动剔除stdin中残留的空白符:
// 因为格式%s不会匹配多余的空白符,这里按回车后,stdin中会残留一个换行符\n
scanf("%s",recvStr);
// 在格式%c前加一个空格,可以吸收掉上面残留的换行符\n,程序便能如预期接受用户输入
scanf(" %c",&recvChar);
然而,这一种方法仅只能剔除多余的空白符。
# 使用中括号字符集
这个解决方法可以和上面剔除空白符的方法进行结合。
格式化输入有一个说明符 %[set],它的功能和正则表达式中的中括号[ ]十分类似:
-
其中
set代表一个用于匹配的字符集,一般情况下匹配的是存在字符集中的字符 -
字符集的第一个字符如果是
^,则表示取反,匹配的是不存在于该字符集中的字符 -
可以在中括号中使用短横线
-来表达一个范围,比如%[0-9]代表匹配0-9之间的字符。值得注意的是,对于短横线-,可能在不同编译器之间有不同实现,它是implementation-defined的。
另还有一个说明符 * ,它被称为赋值抑制或赋值屏蔽符。如字面意思,在%引导的格式转换字串中如果包含*,这个格式匹配的内容不会被赋给任何变量。
于是,可以给出如下的语句:
// 星号 * 代表不会把匹配到的内容赋给变量,相当于“吸收”掉了
// [^\n] 代表除了换行符外一律匹配
scanf("%*[^\n]");
因为用户结束一次输入的标志通常是按回车输入一个换行符,残留的内容往往末尾是一个换行符。上面这句的原理就是吸收掉stdin中所有的残余字符,直至达到最后一个字符,也就是换行符。
然而,换行符不会被上面这句所吸收,所以在接下来的输入中只需要忽略stdin中的残余空白符即可(换行符就是空白符之一):
scanf("%*[^\n]");
scanf(" %c",&recvChar);
这种方法已经可以解决一般情况下的输入残余问题,不过在后续接受格式化输入时还得忽略换行符\n,还是有点麻烦。
# 循环取走残余字符
这一种方法能在清除残余时顺便吸收掉末尾的换行符\n。
取字符需要用到取单个字符的输入函数,这里为了方便,选用的是getchar()。
一般情况下可以这样写:
// getchar() 会从 stdin 中取走一个字符
while(getchar() != '\n')
;
(使用前提:stdin中有残余)
while循环会一直进行,直至getchar()取到的字符为换行符\n为止,这样就可以顺带吸收掉末尾的换行符了,能相对完美地清除掉stdin中的残余内容。
(在行缓冲模式下,用户的一次输入通常以一个换行符结束)
不过咧,还可以考虑更周全点。在getchar()获取字符失败的时候会返回EOF,但此时并不满足while循环的退出条件,对此可以再完善一下:
// 临时储存字符
// 之所以是整型(int),是因为EOF是一个代表 负值整型(通常为-1) 的宏
int tempChar;
// tempChar=getchar()这种赋值语句本身的返回值就是所赋的值
while ((tempChar = getchar()) != '\n' && tempChar != EOF)
;
这样一来,当getchar()失败时,程序执行就会跳出循环。
综上,针对stdin中的残余内容的清除,最建议采用的便是最后这种处理方法。
不过其他的方法也是可以在一些场景中使用的,这就见仁见智了...
# 什么时候会返回EOF
这里提一个题外的点:什么时候getchar()会返回EOF?再进一步想,什么时候程序会认为标准流stdin达到了文件流末尾?
实际上,这里的EOF往往是用户输入的一个特殊二进制值[3],输入方式:
-
在Windows系统下是 Ctrl + Z(F6应该也行)
-
在Linux下是 Ctrl + D
当用户在输入中发送EOF时,标准流stdin就会被标记为EOF,因此getchar()就会获取字符失败而返回EOF。
// 测试用代码
#include <stdio.h>
int main()
{
char testChar;
fprintf(stdout, "Input Char: \n");
testChar = getchar();
if (testChar == EOF)
{
printf("Received EOF\n");
}
else
{
printf("Received a char\n");
}
return 0;
}
EOF在C语言中是一个宏,定义在头文件stdio.h中,其值为一个负值的整型(并不一定是 -1),因此上面用tempChar != EOF来判断getchar()失败。
# 处理残余的语句放在哪里
现在咱已经搞清楚了清除残余的代码,那么这些代码该放在哪呢?
对于标准输出流stdout来说,fflush语句往往放在输出函数执行完成之后,以立刻将输出内容打印到屏幕上:
printf("Hello ");
printf("World!\n");
fflush(stdout);
当然,如果嫌麻烦可以在输出前直接通过setbuf关闭stdout的缓冲:
setbuf(stdout, NULL);
对于标准输入流stdin来说,处理残余的语句往往放在每次输入函数执行之后,以及时清理流中残余内容:
int c;
char testChar1, testChar2;
scanf("%*s"); // * 用于屏蔽赋值
while ((c = getchar()) != '\n' && c != EOF)
;
testChar1 = getchar();
while ((c = getchar()) != '\n' && c != EOF)
;
scanf("%c", &testChar2);
当然,这样就显得有点冗余了。
实际上可以将清除的语句封装进函数或者定义为宏(不过确实不太建议定义为宏),这样也更便于维护。
# 总结
之前浏览了很多相关文章,标题和内容大多都写着“清空输入缓冲区”。现在想一下,这样写可能是不对的,因为实际我清空的是标准输入流stdin中的残留内容。在用户输入完成(输入换行符)的那一刻,输入缓冲区实际上就已经被清空了。
也就是说,标准流和对应的缓冲区要辨别清楚,二者不是同一个概念(一个stream一个buffer),千万不能混淆了。

最后,感谢你看到这里~
本笔记可能还是有错误出现,也请各位多指教!
(今天也是崇拜些瓶老师的一天(〃` 3′〃)
共2条评论